
In the previous article of this series, we saw that cache exists because access to nearby data is orders of magnitude faster than access to distant data, and that this principle applies from processor registers to CDN edge servers. The locality of reference principle, formalized by Peter Denning in 1968, is what makes cache effective: data accessed recently has a high probability of being accessed again soon.
But understanding why cache works is different from knowing how to use it inside a system architecture. A cache placed without criteria in the wrong place, with the wrong integration pattern, can generate inconsistencies that are hard to diagnose, create single points of failure, or simply fail to deliver the expected benefit. This article explores the main cache-database integration patterns, the contexts where each one makes sense, and how the CAP theorem frames the consistency decisions these patterns imply.
The problem the patterns solve
Before presenting the patterns individually, it helps to understand the general problem they all share. A system with cache has two locations where the same piece of data can exist: the cache and the database. The database is the authoritative source, the place where the most recent and reliable version lives. The cache is a copy, possibly older, of part of that data.
The central challenge is keeping these two representations coherent enough for the system to behave correctly from the user's perspective. When and how the cache is populated, when it is invalidated, and who is responsible for writing to the source are the questions that integration patterns answer. Each answer carries a different set of guarantees and limitations.
Cache-aside: the most widely used pattern
Cache-aside, also called lazy loading, is the pattern where the application explicitly controls interaction with the cache. The responsibility of querying the cache, detecting a miss, fetching from the source, and populating the cache falls on the application code.
The read flow starts with the application querying the cache by the key of the desired data. If the data is present (a cache hit), it is returned directly. If it is not present (a cache miss), the application queries the database, stores the result in the cache with a defined TTL, and returns the result to the caller. TTL, or time-to-live, is the maximum time an entry remains valid in the cache before being automatically discarded. From the second access to the same data, within the TTL validity period, the database is not involved.
sequenceDiagram
participant App as Application
participant Cache as Cache (Redis)
participant DB as Database
App->>Cache: GET product:123
alt Cache Hit
Cache-->>App: return data
else Cache Miss
Cache-->>App: nil
App->>DB: SELECT * FROM products WHERE id = 123
DB-->>App: return data
App->>Cache: SET product:123 [data] EX 300
App-->>App: return data to caller
endOne of the most valued properties of cache-aside is resilience to cache failure. If Redis becomes unavailable, the application continues working with performance degradation, as all requests go directly to the database. The system loses performance but maintains correctness.
Another property is the flexibility of the stored data model. Because the application controls what goes into the cache, the stored data can be a transformation of the original, an aggregation of multiple queries, or any structure that fits the application's read pattern. This flexibility disappears in patterns where the cache manages the origin lookup automatically.
The most relevant limitation of cache-aside is the inconsistency window between writes and reads. When data is updated in the database, the corresponding cache entry may remain stale until the TTL expires. This is acceptable for data that tolerates slight staleness, such as a view count or a list of most popular products. For data that needs to reflect the most recent version immediately, such as a bank account balance, this inconsistency window is unacceptable.
The AWS cache patterns documentation, published as a technical whitepaper on Redis caching strategies, describes this pattern as the most suitable for read-intensive workloads where immediate consistency between cache and database is not a requirement.
"A cache-aside cache is updated after the data is requested. [...] When your application needs to read data from the database, it checks the cache first to determine whether the data is available. If the data is available, it's returned to the caller without querying the database."
— AWS, Database Caching Strategies Using Redis, AWS Whitepaper
Cache stampede and the thundering herd
There is a problem that particularly affects the cache-aside pattern under high load and deserves attention before moving on to other patterns. This problem is called cache stampede, a manifestation of the broader phenomenon known as thundering herd. It occurs when the TTL of a highly popular piece of data expires and several concurrent requests detect the same cache miss. The thundering herd describes situations where many processes are awakened simultaneously to compete for the same resource. In the case of cache stampede, multiple requests detect the miss at the same time and end up querying the database in parallel.
Imagine an article with a million readers per day. While the data is in the cache, all requests are served in microseconds. The moment the TTL expires, however, hundreds or thousands of requests arrive simultaneously, all detect the cache miss, and all fire a database query at the same time. The database, which was protected by the cache, is suddenly hit by a volume of requests it was not sized for. Response time rises, the database may start rejecting connections, and the cache takes longer to repopulate because each read operation on the database competing with the others slows down. The problem compounds itself.
Cache stampede is one of the most documented hidden costs associated with cache usage. Specific strategies exist to mitigate it, and they will be explored in detail in the next article in this series, along with other structural and operational costs that cache introduces.
Read-through: delegating responsibility to the cache
In the read-through pattern, the cache acts as an intermediary between the application and the database. The application always queries the cache, and the cache manages the origin lookup when necessary. The difference from cache-aside is that the logic for querying the database and populating the cache lives inside the cache (or an abstraction layer wrapping it), not in the application code.
From the application's perspective, the interaction is straightforward. It requests data from the cache and always receives a response. The cache handles going to the database if needed, storing the result, and returning it. The application does not need to implement miss-handling logic.
This simplifies application code, especially when multiple services or instances need to access the same data. With cache-aside, each instance needs to implement the same miss-handling pattern. With read-through, logic centralized in the cache ensures all callers behave the same way.
The limitation is the first access to any piece of data. Because the cache is only populated when data is requested for the first time, the first user to request a given resource always pays the cost of fetching from the source. A common practice to mitigate this is cache warming, or pre-loading, where the most likely data to be accessed is loaded into the cache during system initialization or during low-traffic periods.
The read-through pattern is particularly well suited for CDNs, which are essentially read-through implementations at global scale. When a user requests an image file served by a CDN, the edge server checks whether it has that file in cache. If not, it fetches from the origin, stores it locally, and delivers it to the user. All subsequent users requesting the same file from the same edge server receive the cached version without involving the origin.
Write-through: keeping cache and database in sync on writes
In both previous patterns, writes always go directly to the database, and the cache is updated reactively, either by TTL or by explicit invalidation. Write-through changes this dynamic. When data is written, the application updates the database and the cache synchronously, before returning confirmation to the caller.
It is important to understand who does what in this flow. Redis operates without native connectivity to relational databases, so the application is responsible for propagating writes to both systems. The recommended order is to write to the database first, wait for confirmation, and only then write to the cache. This sequence ensures that if the system fails between the two operations, the database, the authoritative source of data, will have the correct value. Failing after the database write but before the cache write means only that the next cache access will result in a miss, which is a recoverable situation. Failing after the cache write but before the database write would create a more serious problem, since the cache would hold data the database does not confirm.
sequenceDiagram
participant Caller as Caller
participant App as Application
participant DB as Database
participant Cache as Cache (Redis)
Caller->>App: update product:123
App->>DB: UPDATE products SET ... WHERE id = 123
DB-->>App: confirmation
App->>Cache: SET product:123 [new data] EX 300
Cache-->>App: confirmation
App-->>Caller: confirmationThe benefit is that the cache stays current for data that has gone through recent writes. If a product's price is updated and the system uses write-through, the next read of that product from the cache will already carry the new price, because the write updated both locations in the same operation.
The cost is write latency. The application must wait for both the database and the cache to confirm the operation before continuing. If the database is slow, every write operation in the system becomes slower by the same factor. In systems with high write throughput, this can become a meaningful bottleneck.
There is also a risk of inconsistency in the opposite direction from cache-aside. With cache-aside, inconsistency means the cache is stale relative to the database. With write-through lacking a complementary read pattern, the cache can accumulate data that is never read, occupying memory without benefit. The most common combination in practice is write-through for writes and cache-aside (or read-through) for reads, ensuring the most accessed data is in cache and that writes keep it current.
Write-behind: prioritizing write performance
Write-behind, also called write-back, reverses the priority order of write-through. The application writes to the cache, receives confirmation immediately, and an external process, typically a background worker or a queue consumer, is responsible for reading pending writes from the cache and propagating them to the database asynchronously. Redis itself has no native write-behind mechanism. The application does not wait for the database to confirm directly.
The performance gain is significant in systems with high write throughput. If ten thousand updates arrive in one second, the cache can absorb all of them immediately and send them to the database in a single batch, drastically reducing the number of write operations on the database and eliminating the waiting latency for each individual operation.
The risk is proportional to the benefit. If the cache fails before propagating pending writes to the database, those writes are permanently lost. The database will be in a state prior to what the system believed it had confirmed. For financial data, transactions, or any information that cannot be lost, this risk is unacceptable. For data where occasional loss can be tolerated, such as access statistics, like counters, or low-criticality event logs, write-behind can be a valid choice.
The Oracle documentation for Oracle Coherence, one of the first enterprise distributed cache systems to formally document these patterns, describes write-behind as follows:
"The write-behind pattern changes the timing of the write to the system of record. Rather than writing to the system of record while the thread making the update waits (as with write-through), write-behind queues the data for writing at a later time."
— Oracle, Read-Through, Write-Through, Write-Behind Caching and Refresh-Ahead, Oracle Coherence Documentation
The same Oracle documentation lists a fifth pattern: refresh-ahead, where the cache proactively reloads data before the TTL expires, without waiting for a miss. The advantage is eliminating the first-access latency for data with a predictable and regular access pattern. The limitation is that it requires prior knowledge of which data will be requested, making it more suitable for cases like periodically recalculated rankings or configurations with a fixed update cycle than for data with unpredictable access patterns.
The patterns described so far are tool-agnostic: any cache system can implement them. What changes from tool to tool are the guarantees each pattern offers in practice and the limitations it carries. These differences become clearer when you understand how a tool was built and what problem it was designed to solve.
When the problem defines the tool: the story of Redis
Tools are shaped by the contexts in which they were created. Their design decisions reflect the constraints and needs their creators faced at the time. Understanding that context helps explain why a tool prioritizes certain aspects and where its limits lie.
Salvatore Sanfilippo started the project in 2009 while working at his Italian startup LLOOGG, a web log analyzer with low-latency processing requirements. MySQL could not keep up with the volume of read and write operations needed for near-real-time analysis, so Sanfilippo prototyped an in-memory database in Tcl with around 300 lines of code. After a few weeks of successful internal use, he rewrote the prototype in C, added the list data type, and published the project on Hacker News in February 2009 with the help of David Welton.
The initial response was muted. Few people replied to the original post, and most pointed out that similar projects already existed. Among the positive responses was one from Ezra Zygmuntowicz, a developer well known in the Ruby on Rails community, who produced one of the first Ruby clients for Redis. That work opened the doors for Redis adoption in the Ruby community, which included GitHub and Instagram among its first production users.
Instagram, launched in October 2010, was built entirely on Redis in its early years. The original architecture, documented in technical presentations by Mike Krieger, co-founder of the company, used nginx, Redis, memcached, PostgreSQL, Gearman, and Django. Redis was central to the photo feed, like and follower counters, and user sessions.
The Instagram story with Redis illustrates both the power and the limitations of the approach. In its rapid growth, reaching 15 million users by mid-2011 before even launching the Android app, Redis absorbed loads that would have destroyed a purely relational database architecture. But as Instagram grew further, it migrated parts of its infrastructure to Apache Cassandra, particularly for data that required more aggressive horizontal scalability and fault tolerance with guaranteed availability.
That migration reflected the recognition that different tools are designed for different trade-offs, and that Redis, with its in-memory data model and asynchronous replication, was optimized for speed over strong consistency. Understanding that design choice is necessary before analyzing where Redis sits within the CAP theorem.
The distributed context and the CAP theorem
Up to this point, the patterns have been described in the context of a single cache server interacting with a database. In distributed systems with multiple cache instances, multiple database nodes, and multiple geographic regions, the consistency question becomes more complex.
In 2000, Professor Eric Brewer of the University of California, Berkeley, presented at the Symposium on Principles of Distributed Computing a conjecture that became known as the CAP theorem. In 2002, Seth Gilbert and Nancy Lynch of MIT published the formal proof. The theorem states that any distributed data system can guarantee at most two of the following three properties at the same time.
The first property is consistency, where every read receives the most recently written data, or an error. The second is availability, where every request receives a response, without a guarantee that it contains the most recent data. The third is partition tolerance, which ensures the system continues operating even if communication between nodes is lost.
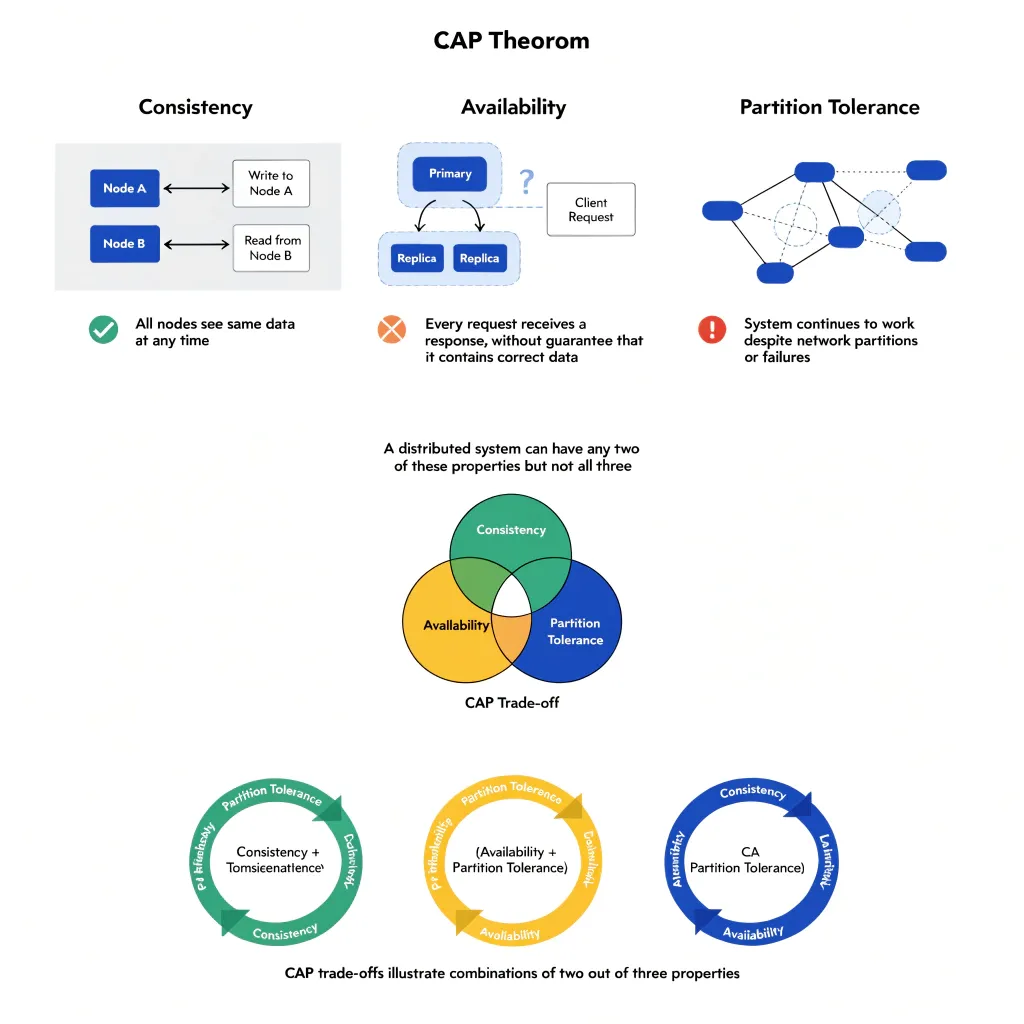
"A distributed data store can only provide two of the following three guarantees: consistency, availability, and partition tolerance."
— Eric Brewer, Towards Robust Distributed Systems, PODC Keynote, 2000, formalized by Gilbert and Lynch in Brewer's Conjecture and the Feasibility of Consistent, Available, Partition-Tolerant Web Services, ACM SIGACT News, 2002
In distributed systems in production, network partitions are inevitable. A cable can be cut. A datacenter can become temporarily isolated. A node can fail and lose connectivity with the others. In practice, the choice reduces to a tension between consistency and availability during a partition.
Cache has a direct relationship with this trade-off. A cache that always returns local data, even when uncertain whether it is current, prioritizes availability. A system that invalidates the cache and queries the source during any consistency uncertainty prioritizes consistency, but may degrade performance or fail completely if the source is unavailable.
How cache tools position themselves within the CAP theorem
Every distributed cache tool occupies some place in the space bounded by the CAP theorem, and that position depends both on the tool's design choices and on how it is configured. Redis is the most widely used tool in this context, and its analysis illustrates the trade-offs any similar system faces. Claiming that Redis is simply a CP system, one that guarantees consistency and partition tolerance at the cost of availability, would be a simplification that obscures important trade-offs. The answer depends on how Redis is configured and which specific guarantees are being evaluated.
To start, the CAP theorem applies to systems with multiple nodes that need to maintain replicated data. In a single-node configuration, Redis functions like any conventional in-memory database, and the question of network partitions simply does not arise. The node is either available or it is not.
The picture changes when replication is added. Redis, by default, uses asynchronous replication between the primary node and its replica nodes. This means a write confirmed by the primary may not have reached the replicas at the moment of confirmation. If the primary fails and a replica is promoted to new primary before receiving all pending writes, those writes are permanently lost. Martin Kleppmann, in his book Designing Data-Intensive Applications published by O'Reilly in 2017, describes exactly this scenario when discussing replication:
"Because the replication is asynchronous, a follower may fall behind the leader [...] If the leader fails and you promote a follower to be the new leader, any writes that have not been replicated to the new leader will be lost."
— Martin Kleppmann, Designing Data-Intensive Applications, O'Reilly, 2017
This behavior places Redis with asynchronous replication among AP systems, those that prioritize availability and partition tolerance over strong consistency. In practical terms, Redis with asynchronous replication can confirm writes that do not survive a failover. The post-failover database will be in a different state from what the client believed it had confirmed.
The behavior moves closer to CP in Redis Cluster when one side of a partition loses quorum. In that case, the cluster refuses writes on the minority side, preserving consistency at the cost of becoming unavailable. But this protection is limited. Writes accepted before the partition is detected can still be lost if the primary node fails during the uncertainty window.
The honest conclusion is that Redis, in its default configuration with asynchronous replication, prioritizes low latency and high availability. Eventual consistency is the direct consequence of that design choice.
For cases where the loss of confirmed writes is unacceptable, it is important to distinguish two different problems.
The first involves durability against process crashes. AOF mode with appendfsync always ensures each write is persisted to disk before being confirmed, protecting against data loss on server restarts.
The second involves durability against replication failovers. Even with synchronous AOF active on the primary, writes that were not replicated before the failover remain vulnerable, because the risk comes from the replication lag between primary and replica, regardless of how data was persisted locally. For this case, Redis offers the min-replicas-to-write and min-replicas-max-lag settings, which cause the primary to refuse writes when there are not enough sufficiently up-to-date replicas, or the WAIT command, which blocks the confirmation of a specific write until a minimum number of replicas has received it. Any of these approaches implies additional latency, and for strong consistency requirements without compromise, tools designed with that goal from the start are the more appropriate alternative.
Tools like Apache Cassandra and Amazon DynamoDB offer even more granular control, allowing the client to define the quorum required for each read and write individually. That granularity confirms that consistency and availability form a spectrum adjustable per operation, with each request able to calibrate the right balance for its context.
Brewer revisited the CAP theorem in 2012, refining the original analysis to recognize exactly that point.
"The modern CAP goal should be to maximize combinations of consistency and availability that make sense for the specific application. Such an approach incorporates plans for operation during a partition and for recovery afterward."
— Eric Brewer, CAP Twelve Years Later: How the 'Rules' Have Changed, IEEE Computer, 2012
That perspective guides caching decisions in systems with a well-defined caching strategy. For product catalog data, availability with slight temporal inconsistency is acceptable, since showing a price a few seconds out of date does not compromise the user experience. For inventory data with continuous updates, consistency matters more, since selling a product that has already sold out has a direct business consequence.
Distributed cache: replication and consistency across instances
When a system has multiple cache instances, or multiple nodes in a Redis cluster, the question of how to maintain consistency among them arises. If two cache nodes have different versions of the same data, which version is correct? How do you ensure that an invalidation made by one application instance is propagated to all cache nodes that may hold a copy of the data?
Redis Sentinel and Redis Cluster are the two main solutions to this problem. Sentinel provides high availability for a single primary with its replicas, performing automatic failover. If the primary node fails, Sentinel detects the failure through a vote among Sentinel processes, promotes one of the replicas to primary, and reconfigures clients to point to the new primary. Cluster distributes data across multiple nodes through hash slots, divided into 16,384 fixed positions. Each key is mapped to a slot via CRC16(key) mod 16384, and each slot is assigned to a specific cluster node. This approach ensures that when adding or removing nodes, only the slots of the affected node need to be redistributed.
In both cases, there is a replication lag between the primary and the replicas. Writes confirmed on the primary can take a few milliseconds to appear on the replicas. During that interval, a read from a replica may return stale data. This is eventual consistency in action, where the system converges toward consistency, but there is a period when different replicas hold different states.
graph TD
App1[App Instance 1] --> Primary[Redis Primary]
App2[App Instance 2] --> Primary
Primary -->|async replication| Replica1[Redis Replica 1]
Primary -->|async replication| Replica2[Redis Replica 2]
App3[App Instance 3] --> Replica1
App4[App Instance 4] --> Replica2
Sentinel[Redis Sentinel] -.monitoring.-> Primary
Sentinel -.monitoring.-> Replica1
Sentinel -.monitoring.-> Replica2For most web applications, this temporary inconsistency is acceptable. A user who updates their profile and immediately reloads the page may see the previous version for a fraction of a second. That is rarely a noticeable problem. But for financial applications, reservation systems where two users cannot book the same resource, or any system where reading stale data can lead to an incorrect action, asynchronous replication needs to be handled carefully.
Local in-memory cache and the coherence cost
Beyond distributed cache like Redis, many systems use local in-memory cache inside each application instance. This is implemented with data structures directly on the JVM heap, the Python process, or the Go runtime. The access latency is lower still, since it eliminates the network and serialization overhead that any remote cache carries. An access to an in-memory map takes nanoseconds, while a network call to Redis takes microseconds.
The cost of local cache is coherence across instances. If an application has ten instances running in parallel, each one has its own local cache with its own version of the data. When data is updated, such as a product price, only the instance that made the update knows about it. The other nine instances continue serving the old price until their TTLs expire or until they receive an invalidation notification.
This absence of coherence is tolerable for highly static data, such as system configurations that rarely change or country lists that never change. For data that can change frequently, local in-memory cache introduces inconsistency windows proportional to the TTL, multiplied by the number of application instances.
An intermediate solution is combining local cache with distributed cache in two layers. The application queries the local cache first. If not found, it queries Redis. If not found in Redis, it goes to the database. Invalidation can be propagated via Redis pub/sub, where all instances subscribe to a channel and receive notifications when data is invalidated, allowing them to remove the entry from their local cache.
Integration with event-driven systems
In architectures that use message queues or streaming systems such as Apache Kafka, cache can be integrated into the event flow to keep data more current than TTL allows.
When an update event is published, such as a PriceUpdated event for a product, a consumer of that event proactively invalidates or updates the corresponding cache entry. This is called event-driven invalidation, and it eliminates the TTL inconsistency window for data that has corresponding events in the system.
The advantage is that the cache reflects the current state of data almost instantly, without depending on a fixed expiration interval. The disadvantage is greater complexity, as the cache system becomes dependent on the messaging system. If the queue falls behind or loses messages, the cache can become stale without any automatic recovery mechanism, unlike the TTL.
The priorities each pattern carries
Each cache pattern reflects a choice about what the system prioritizes. Cache-aside with a long TTL prioritizes read performance at the cost of tolerating slightly stale data. Write-through prioritizes consistency at the cost of higher write latency. Write-behind prioritizes write throughput at the cost of accepting data loss risk on failure. Local cache prioritizes minimum latency at the cost of coherence across instances.
No pattern is universally superior. The choice depends on the data type, the access pattern, business consistency requirements, and tolerance for data loss risk. Systems with a well-defined caching strategy apply different patterns to different data types within the same application. Write-through for financial data, cache-aside with a short TTL for profile data, local in-memory cache for static configurations.
Pattern comparison
| Pattern | Consistency | Write latency | Loss risk | Typical use case |
|---|---|---|---|---|
| Cache-aside | Eventual (TTL) | Low (writes go directly to database) | None (stale data at most) | Read-heavy workloads tolerating slight staleness |
| Read-through | Eventual (TTL) | Low (writes bypass the cache) | None | CDNs, public data with high read volume |
| Write-through | Strong (for recent writes) | High (database and cache synchronous) | None | Data requiring consistent reads after writes |
| Write-behind | Eventual (asynchronous) | Very low (immediate confirmation) | High (pending writes lost on failure) | Counters, logs, low-criticality statistics |
| Refresh-ahead | Eventual (anticipated TTL) | N/A (read optimization) | None | Rankings, configurations, data with regular and predictable access |
In the next article in this series, the focus shifts to the costs that cache introduces, whether financial, operational, or cognitive. Cache invalidation is recognized as one of the hardest problems in software engineering, and the cost of getting it wrong goes well beyond the occasional stale value a user sees.
